
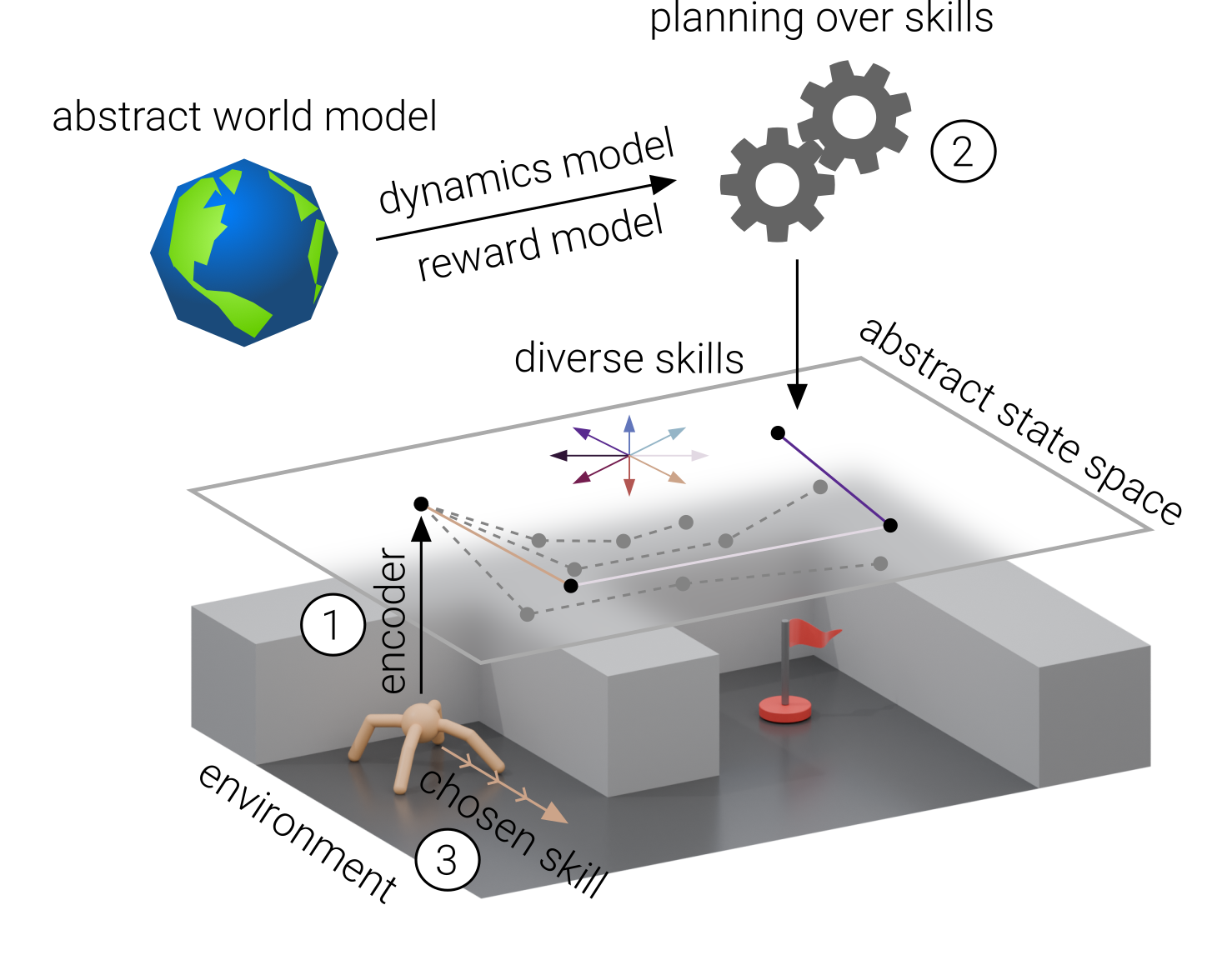
Model-based reinforcement learning (RL) leverages learned world models to plan ahead or train in imagination. Recently, this approach has significantly improved sample efficiency and performance across various challenging domains ranging from playing games to controlling robots. However, there are fundamental limits to how accurate the long-term predictions of a world model can be, for example due to unstable environment dynamics or partial observability. These issues are further exacerbated by the compounding error problem. Model-based RL is therefore generally limited to short rollouts with the world model, and consequently struggles with long-term credit assignment. We argue that this limitation can be addressed by modeling the outcome of temporally extended skills instead of the effect of primitive actions. To this end, we propose a mutual-information-based skill learning objective that ensures predictable, diverse, and task-related behavior. The resulting skills compensate for perturbations and drifts, enabling stable long-horizon planning. We thus introduce Stable Planning with Temporally Extended Skills (SPlaTES), a sample-efficient hierarchical agent consisting of model predictive control with an abstract skill world model on the higher level, and skill execution on the lower level.
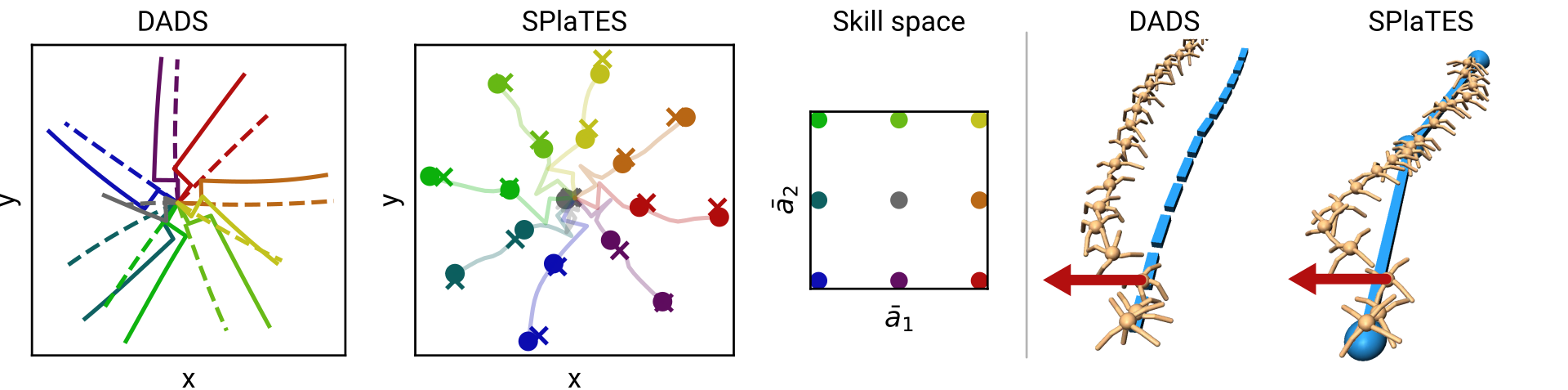
Left: Skills applied to a velocity-controlled point mass under a perturbation.
DADS: Predictions are marked by dashed lines.
SPlaTES: Predictions of the abstract world model are marked by crosses, actual states at the end of
skill executions by circles.
SPlaTES compensates the perturbation and stays close to the prediction while DADS cannot recover from
it.
Right: Execution of a fixed skill sequence with a quadruped.
A force is applied in one time step (red arrow). SPlaTES corrects the resulting deviation while DADS
cannot.
@inproceedings{
gurtler2025longhorizon,
title={Long-Horizon Planning with Predictable Skills},
author={Nico G{\"u}rtler and Georg Martius},
booktitle={Reinforcement Learning Conference},
year={2025},
url={https://openreview.net/forum?id=G8ybRSxO10}
}